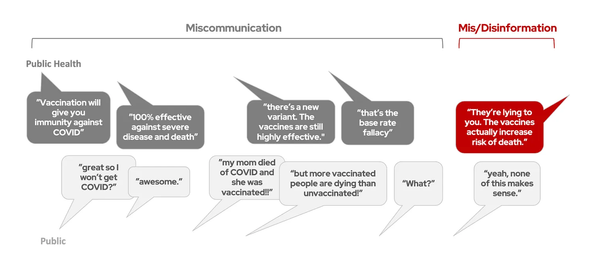
A case study in graphs that crush my soul


I am a data visualization nerd. Even as a kid I was stealing my dad’s graph paper and finding random things to chart. When my mom was recently asked what each of her kids were into when they were young, her answer for me was “data.” (Also kittens.)
Graphs are central to scientific communication, and when used appropriately are amazing tools that help people understand complex data. But with a few small changes, graphs can also be used to mislead and distort what’s going on.
Recently I came across a graph (published by a prominent physician) that was so bad that it deserves its own entire post. I originally wrote about it here, and by request I’m adding it to the blog as well, as it teaches some basic points on how graphs can be constructed to mislead and how the risk of just about anything can be made to “seem” small or large, depending on how you slice and dice the data.
How to mislead with graphs
Recently a study was published assessing the effectiveness of the Pfizer COVID vaccine in kids (age 5-11) against omicron. It analyzed data from 255,936 kids in Singapore from Jan-Apr 2022 to see who was vaccinated, who got COVID, and who was hospitalized.
Vaccination for this age group started in Singapore right before the study started (Dec 2021), and the majority of kids were vaccinated during the study period (Jan-Apr ’22). They tracked timing of vaccination and infections to calculate vaccine effectiveness for partially and fully vaccinated kids.
The study found that the vaccine effectiveness against hospitalization from omicron remains quite strong: 83% effectiveness in fully vaccinated kids. (As a side note, if 83% effectiveness seems “not that great” to you, read this.)
In response to this study, a physician with a large platform decided to reframe these results with this graph published on his substack:
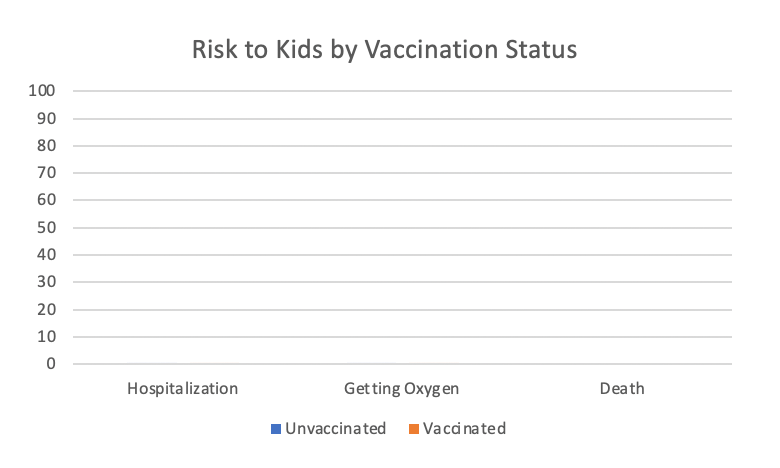
Reproduced version of graph. Not linking to the original substack article because I am uninterested in spreading it.
You can’t even see the data (which seems to be the intended point.)
This graph misleadingly suggests that the risk of hospitalization by COVID for kids is so small that getting vaccinated or not doesn’t matter. It’s basically 0!
While perhaps visually persuasive, this makes some very basic errors that mislead and misrepresent the data. Let’s go through them.
Lesson #1: Inappropriate axis scales are misleading
The y-axis of this graph is distorted by setting the max value too high. This is one of the oldest tricks in the book of how to mislead with graphs: if you would like your data to seem small, just set the axis to an inappropriately large number, and it will look tiny!
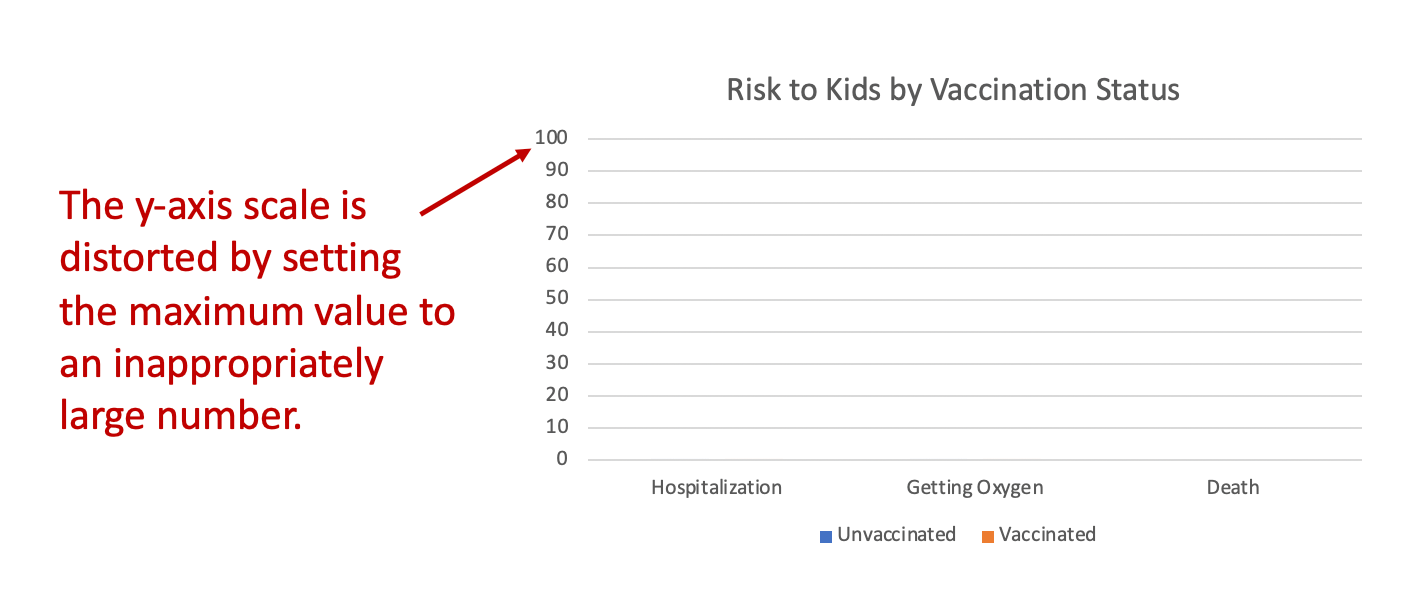
Generally, we set our axis labels so they are about 10-20% higher than the highest value in our data set. Anything much higher than this will automatically make the data seem low, because our eyes are intuitively comparing it to the top of the y-axis.
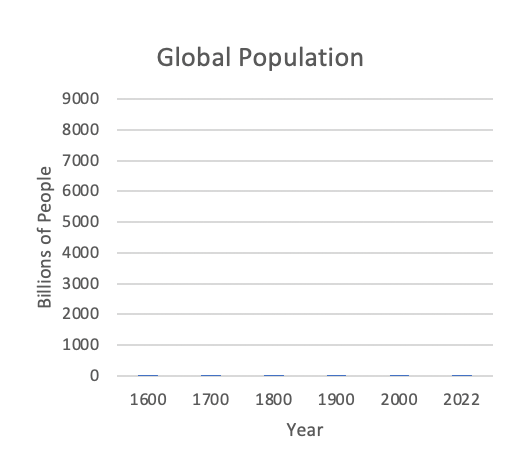
For example, look at these two graphs, both of which contain identical data, but the y-axis is set to different values:
There's hardly any people!
Jk.
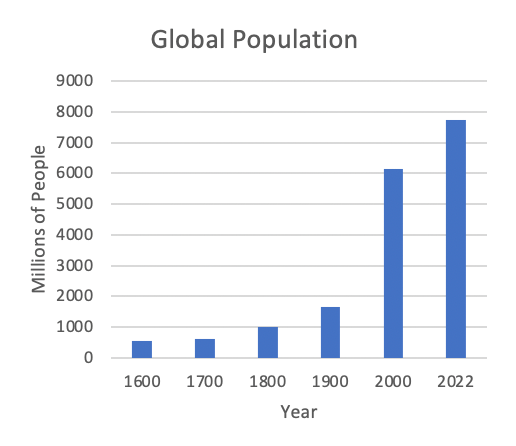
This example probably seems silly because most people already have an intuitive sense that there are a lot of people on planet Earth, so they are unlikely to be duped by the graph on the left. But when it comes to a topic people are less familiar with like vaccine efficacy, they are more easily mislead.
The data should determine the y-axis. The axes should always be set so the data can be seen easily and intuitively. Artificially changing an axis scale to a significantly different range than what’s reflected in the data is often a means to purposefully deceive the viewer, and there is rarely a valid scientific reason to do it.
Lesson #2: Unlabeled data is largely useless
The chart title says this represents the “Risk to Kids by Vaccination Status.” But risk of what? Risk of hospitalization each day? Risk of hospitalization over the course of the whole study? Risk for those who tested positive? Risk for all kids in the study?
The calculated risk will vary dramatically depending on the answers to these questions. And there is no axis label to tell us which risk the graph is referencing.
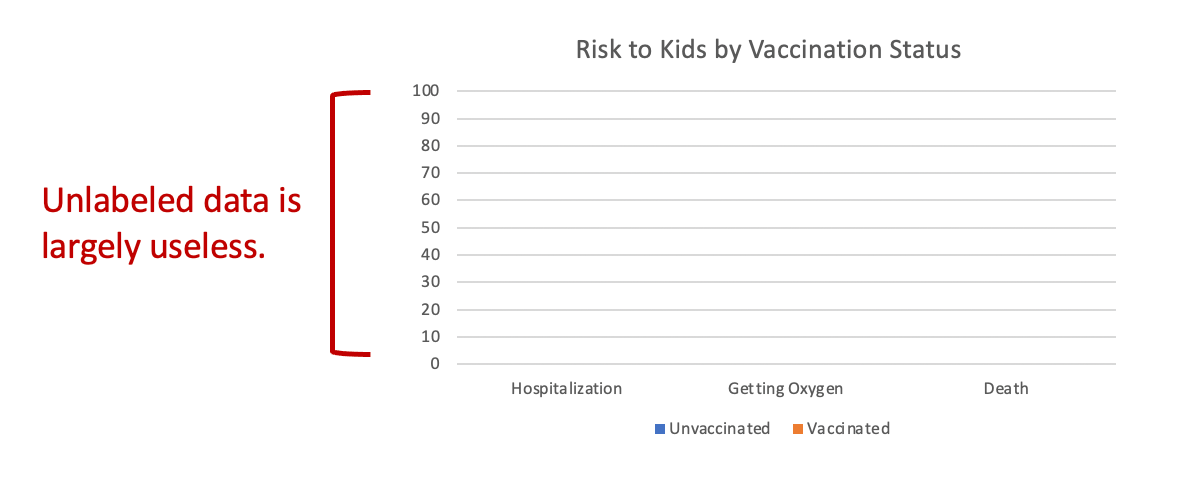
The “zoomed up” version of the graph included in the substack article is also missing the axis label:
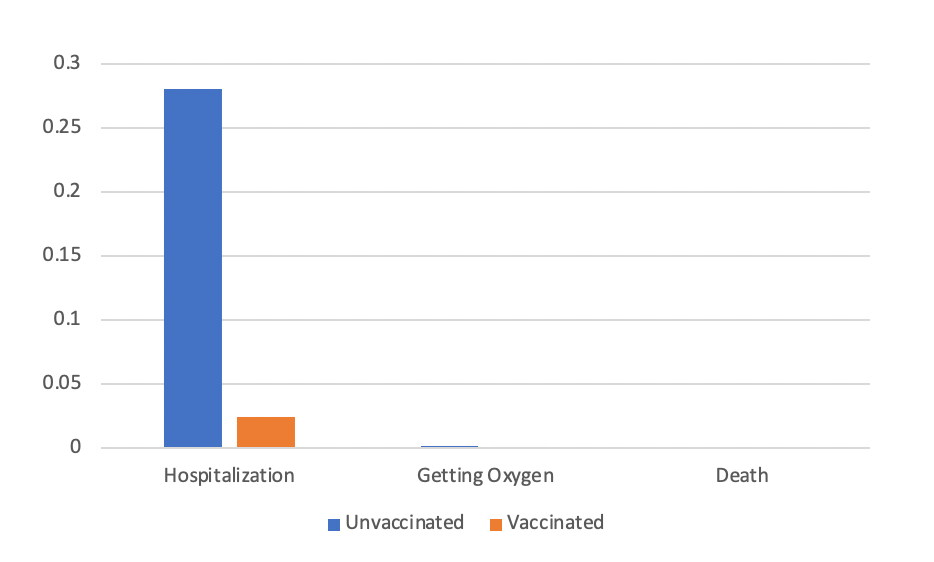
Reproduced version of graph. Not linking to the original because I am uninterested in promoting their article.
To figure out what risk this graph is referencing, I tried to match the data presented here with the results reported in the NEJM study. First, let it be noted that I shouldn’t have to do this. Graphs should be clearly labeled so that it’s very obvious what they are referencing. Nebulous labels are sometimes an accidental artifact of an academic’s busy life (they forgot or did not have time to label it well), but they can also be used to deceive. By making it vague what data is presented in a graph, people viewing it will fill in the blanks on their own, often inaccurately. This can accidentally or purposefully mislead viewers into believing the data shows one thing, when in fact it shows something else.
After reviewing the original NEJM article in detail, the only analysis that matches the data in this graph came from dividing total hospitalizations in each group by the total number of vaccinated and unvaccinated kids at the end of the study. This is not the correct way to analyze the data (and not the way the NEJM study did it) because it fails to account for the majority of kids who got vaccinated during the study.
If I’m correct, then this graph doesn’t faithfully represent anything meaningful in the paper. But I don’t know for sure, because, again, we have no axis label to tell us what data we’re looking at.
Lesson #3: Risk depends on population and time
As the graph doesn’t appear to accurately represent the analysis from the original NEJM study, we can’t infer much of anything from it. But as a thought experiment, let’s imagine for a second that this graph truly represented the risk of hospitalization from COVID for all children in the study over the course of the study period (about 2.5 months). Is a quarter of a percent risk of hospitalization (1 in 400 kids will be hospitalized within 2.5 months) so small that we should not worry about it?
To answer this question, you need context. You can make the risk of practically anything “seem” small or big depending on how you slice and dice the data.
For example, the average risk of all cause death for everyone in the US over the same time period (2.5 months) is about 0.2%. That’s hundreds of thousands of deaths, but the percentage “seems” small because we’re looking across the entire population.
To assess if a quarter of a percent of kids getting hospitalized with COVID over 2.5 months is a “big deal”, you have to compare to other risks to kids over the same time period. You can’t just look at a single number and say “that’s super small!” and decide it’s insignificant. Sometimes risk is reported per day, sometimes per week, sometimes per month, sometimes per year, and sometimes per lifetime. The risk of the same event will yield a different percentage depending on which of these time periods is used. If it’s risk per day, the number might seem super small, but when it’s taken in aggregate over a year or lifetime, it becomes much larger.
You also have to compare to risks in the same population. For example, it’s not a fair comparison to look at the risk of death for an 80-year-old and a 8-year-old and say “well it’s way lower for the 8-year-old, so it doesn’t matter!” The risk of death from practically everything is lower for an 8-year-old compared to an 80-year-old. If the standard by which we measure the “significance” of pediatric illness is by comparing it to illness in the elderly, then we will have to give up caring about the vast majority of childhood illness from any cause, as the elderly are at much higher risk of illness and death generally. Despite this skew, it is fully justified to put significant effort behind preventing illness in the young, even when the absolute number of those impacted are lower.
To decide how “big of a deal” COVID is for children, compare it to other pediatric diseases, not adult hospitalization rates. Here’s one article that does a good job of putting pediatric COVID into context.
Lesson #4: 'That number seems small!' is not a reliable way to assess risk
A theme that has circulated widely in COVID times is the idea that if a risk isn’t attached to a “big number”, then it doesn’t really matter. For example, a common refrain circulating in 2020 was “The risk of death from COVID is small, 98% survive!”
I understand why people gravitate towards these interpretations. Assessing risk is complex, and deciding if the percentage seems “big” or “small” makes the job easier.
But this often inaccurate, because a small percentage of a very very big number can still be a very big number. Risk is complex, and it must be put into context to make an accurate assessment of how “big of a deal” that risk is.
Don't mislead with graphs
In conclusion, inappropriate axis scales are misleading, unlabeled data is largely useless, risk depends on the population and time period, and determining if risk is significant requires putting it into context, not just deciding if the percentage seems like a small number.